
AI is transforming workforce contingency planning by enabling systems to monitor, predict, and respond to disruptions in real time. This approach moves beyond static, reactive plans and ensures businesses remain resilient during unexpected challenges. Here’s a quick breakdown of how to effectively integrate AI into your contingency strategy:
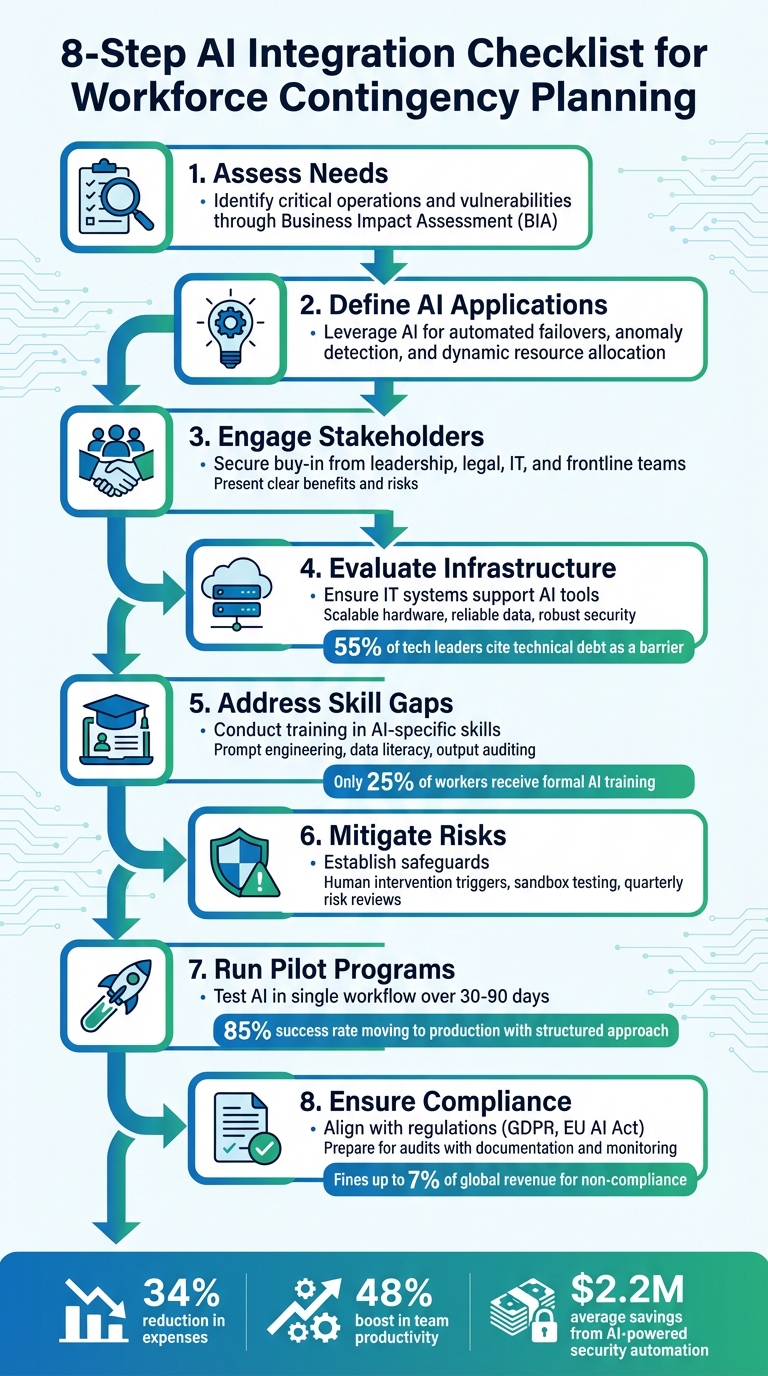
- Assess Needs: Identify critical operations and vulnerabilities through a Business Impact Assessment (BIA).
- Define AI Applications: Leverage AI for tasks like automated failovers, anomaly detection, and dynamic resource allocation.
- Engage Stakeholders: Secure buy-in from leadership, legal, IT, and frontline teams by presenting clear benefits and risks.
- Evaluate Infrastructure: Ensure your IT systems can support AI tools with scalable hardware, reliable data sources, and robust security.
- Address Skill Gaps: Conduct training in AI-specific skills like prompt engineering and data literacy or outsource customer support expertise.
- Mitigate Risks: Establish safeguards like human intervention triggers, sandbox testing, and regular risk reviews.
- Run Pilot Programs: Test AI in a single workflow over 30–90 days with clear success metrics.
- Ensure Compliance: Align with regulations like GDPR or the EU AI Act, and prepare for audits with detailed documentation and monitoring.
8-Step AI Integration Checklist for Workforce Contingency Planning
Write a contingency plan for your business with AI
sbb-itb-8132e49
Assess Business Needs and Objectives
Before introducing AI tools into your contingency planning, it’s essential to determine exactly where they can make a difference. Start with a Business Impact Assessment (BIA) to pinpoint critical operations, acceptable downtime, and resource priorities during disruptions. This process helps uncover vulnerabilities that AI could address. By mapping these risks, you can clearly define where AI fits into the bigger picture.
Take Walmart’s 2025 implementation of its AI Detect and Respond (AIDR) platform as an example. Using over 3,000 machine learning models to monitor system health, the platform covered 63% of incidents in just three months. It also slashed detection times by over seven minutes compared to manual methods. This shows how aligning AI tools with specific challenges can yield measurable results.
Define AI Use Cases in Contingency Plans
Once vulnerabilities are identified, focus on high-impact AI applications. For instance, automated failovers can ensure uninterrupted 24/7 service availability. Similarly, AI-powered chatbots can handle customer support overflow during crises, providing consistent responses without straining human teams.
Other practical uses include:
- Automating incident detection and response by analyzing system logs and network traffic for anomalies.
- Dynamically balancing server loads to optimize resource allocation.
- Strengthening remote workforce security by adapting to new cybersecurity threats in real time.
- Setting AI-monitored thresholds to trigger specific contingency plans or escalate issues.
With these use cases in place, the next step is to bring key stakeholders on board to support these initiatives.
Align Stakeholders and Secure Buy-In
To successfully integrate AI into your contingency plan, collaboration across teams is a must. Leadership, IT, operations, HR, and security all play critical roles. For example:
- Leadership ensures alignment with strategic goals and approves budgets.
- Legal teams review vendor contracts and data usage policies.
- Frontline staff document workflows and flag edge cases that AI must account for.
Building a strong business case is key to gaining stakeholder support. Focus on how AI can reduce risks and cut costs. Transparency is also vital – maintain a clear list of AI vendors and notify stakeholders at least 30 days before introducing new tools or changing data usage terms. Finally, run cross-functional simulations to clarify team roles during potential AI failures. This ensures everyone is prepared to act when it matters most.
Evaluate Technology Readiness for AI Integration
Before deploying AI, it’s crucial to confirm that your infrastructure is ready to handle the demands of these systems. A strong foundation ensures AI tools can deliver consistent and reliable results, especially in critical areas like failover and incident response. According to a 2024 McKinsey survey, 65% of companies now use generative AI in at least one business function, a figure that has doubled in just a year. Yet, 55% of technology leaders cite "technical debt" as a significant barrier to achieving strategic goals like AI implementation. This makes a detailed infrastructure review and readiness assessment an essential first step.
Audit Current IT Infrastructure
Start by assessing your computing resources. AI applications, particularly those leveraging deep learning, rely on high-performance hardware like GPUs and TPUs. Evaluate whether your current environment – whether cloud-based, on-premises, or hybrid – can handle scalable model hosting and auto-scaling.
Your data infrastructure also needs close examination. Ensure your data lakes, warehouses, and catalogs provide accessible, high-quality, and complete data sources. Without reliable data, the insights AI generates will fall short of expectations, much like the common misconceptions about outsourcing customer support when quality isn’t prioritized.
Another critical area is networking capacity. AI systems require networks capable of managing high-speed, data-heavy traffic. At the same time, cybersecurity measures – such as encryption, access controls, and incident response protocols – must comply with regulations like GDPR and CCPA. Finally, confirm that your infrastructure supports robust logging, monitoring, and traceability features. This includes tracking model freshness and response times to ensure AI systems operate efficiently.
Once you’ve optimized your IT infrastructure, it’s time to focus on how these resources connect with AI tools.
Test Integration Points
After auditing your infrastructure, examine how AI will integrate with your existing systems. Determine whether integration will occur in real-time or through batch processes, and confirm API compatibility. Catalog your APIs and identify any legacy systems that might create compatibility challenges. Without modern integration patterns, AI systems may struggle to access critical data.
Next, implement failover mechanisms to ensure business continuity. Distribute AI resources across multiple regions and use tools like Azure API Management to manage load balancing and circuit breaker patterns. For AI inferencing endpoints, consider blue-green or canary deployment strategies to enable smooth, zero-downtime testing.
To validate your system’s resilience, simulate potential failures such as throttling errors, backend timeouts, or service outages. These tests help confirm that retry and circuit-breaking logic functions as intended. By addressing these areas, you’ll ensure your AI tools are prepared to perform reliably, even during unexpected disruptions.
Address Workforce Skill Gaps and Training
Building an AI-ready infrastructure isn’t just about technology – it’s about having a team that can keep up. Right now, there’s a big gap in AI-related skills. Only 25% of workers receive formal AI training, even though 73% of CEOs see AI adoption as a top priority. This mismatch can seriously hold companies back. In fact, organizations with well-trained teams see 3.8 times higher returns on their AI investments compared to those with less structured approaches.
Identify Skill Gaps for AI Use
Your IT systems might be ready for AI, but is your workforce? A good starting point is a skills audit to pinpoint gaps. Focus on these critical areas:
- Prompt engineering: Writing precise instructions to guide AI tools.
- Data literacy: Understanding AI dashboards, assessing data quality, and interpreting results.
- Output auditing: Spotting issues like biases, hallucinations, or compliance risks.
Don’t forget the importance of human oversight skills. AI often works on a "human-on-the-loop" model, meaning employees need to monitor its decisions and step in when things go wrong. With professional skills becoming outdated in less than five years, continuous training is no longer optional – it’s a must.
Use Outsourcing for AI-Augmented Support
Building an in-house AI-savvy team takes time and money. That’s where outsourcing can be a game-changer. It offers quick access to experts skilled in areas like prompt design, output auditing, and AI governance. For example, Aidey provides 24/7/365 SaaS customer support, handling recruitment, training, and system setup at no extra cost. It’s a fast and efficient way to bridge the skills gap without overloading internal resources.
Develop Risk Mitigation and Governance Protocols
Once your team is trained, the next step is to shield your organization from risks unique to AI systems. These systems can sometimes fail without warning, degrade in performance over time, or even cause chain reactions that disrupt interconnected systems. Without safeguards in place, such risks can derail even the most well-thought-out contingency plans.
Identify and Mitigate AI Risks
AI systems face challenges like performance drift, overdependence on their outputs, and security threats such as adversarial attacks. Any of these can compromise essential operations during critical moments.
To counter these risks, set up checkpoints by defining clear triggers for human intervention in high-stakes scenarios. Use confirmation prompts to verify outputs before they’re acted upon. Test new models in sandbox environments using benchmark datasets to ensure reliability. Additionally, conduct quarterly risk reviews for high-risk systems and annual assessments for lower-risk ones.
These measures, built on your existing infrastructure and team readiness, provide a safety net against emerging AI challenges. They also create a foundation for governance frameworks that ensure accountability in AI operations.
Establish Governance Frameworks
Governance is about setting clear rules and responsibilities for managing AI. A good starting point is the NIST AI Risk Management Framework (AI RMF), developed with input from over 240 organizations. It focuses on trust-building elements like safety, security, and fairness. Similarly, Microsoft’s Cloud Adoption Framework complements NIST by emphasizing Responsible AI principles, including transparency and accountability.
"AI governance is no longer a policy layer attached to innovation. It is the control architecture that determines how safely and how fast AI can scale inside an organization." – Robert X, Author, AI Competence Framework
To enforce policies effectively, use tools like Azure Policy or Microsoft Purview to monitor AI systems in real time and immediately address any violations. Prepare incident response plans tailored to AI-specific failures, such as procedures for rolling back to a previous model version or restricting API access when unsafe behaviors are detected. Introduce whistleblower policies to encourage employees to report ethical concerns or critical AI issues without fear of retaliation. Finally, assign an executive owner with the authority to escalate and resolve major AI-related incidents.
Plan and Execute Pilot Programs
Once you’ve established governance and risk protocols, it’s time to test AI in real-world workflows. But here’s the catch: about 95% of AI pilots fail to deliver measurable business outcomes because companies often bite off more than they can chew. To avoid this, limit your pilot to a manageable 30–90 days, focusing on a single, specific workflow.
Prioritize High-Impact Use Cases
Start by targeting repetitive, rules-based tasks that take up employee time but require minimal judgment. Think password resets, order status updates, or resume screening during hiring surges. These tasks are ideal for quick wins.
To narrow your focus, use an impact-effort matrix. Prioritize workflows that promise high business value – like reducing errors or reducing support costs – while posing minimal reputational risk if they don’t pan out. For example, in customer support, focus on the top 15–20% of queries that account for 70% of the volume. Document your current workflow by measuring metrics like hours spent, error rates, and downstream costs. This baseline will help you gauge success.
Set clear success criteria. For instance, achieving a 20% improvement over your baseline or hitting 90% accuracy could justify scaling after the pilot.
"The best way to predict the future is to invent it. Start with a focused pilot that proves value." – Ali, Founder, PilotFrame
Once you’ve identified high-impact use cases, design your pilot tests to validate and integrate these solutions effectively.
Run Pilot Tests
Divide your pilot into three distinct phases:
- Days 1–30: Validate the concept and measure its impact.
- Days 31–60: Integrate with production systems, address edge cases, and complete security reviews.
- Days 61–90: Operationalize the deployment and set up monitoring systems.
Start in shadow mode, where AI generates responses that are reviewed and approved by humans. This approach builds trust and generates training data without jeopardizing operations. Use a 90% confidence threshold, ensuring that outputs below this level trigger human intervention. Monitor 2–3 key metrics throughout the pilot, such as processing time, error rates, or deflection rates. Following this structured approach, pilots have an 85% success rate in moving to production, often delivering an ROI of over 300%.
To avoid falling into "pilot purgatory", keep your scope tight: one workflow, one team, one location. Extending your pilot beyond 90 days increases the risk of it being deprioritized by 8–12% for every additional week. Protect your core operations by defining rollback triggers and implementing a kill switch to halt underperforming pilots if necessary.
Complete Final Deployment and Compliance Checks
After completing a successful pilot, the next step is to secure formal approvals and ensure compliance to avoid potential regulatory fines. This phase transitions your AI system from pilot testing to full production, focusing on leadership approvals and technical safeguards to maintain smooth, continuous operations. Failure to comply with frameworks like the EU AI Act could result in penalties as high as 7% of your global annual revenue. Additionally, over 100 AI-related regulatory actions have already been initiated under US Executive Order 14110 as of mid-2025. This stage builds on the pilot’s outcomes, integrating essential safeguards and compliance measures for full-scale deployment.
Secure Leadership and Compliance Approvals
Start by obtaining formal sign-offs from a cross-functional governance committee. This committee should include key figures like your Data Protection Officer (DPO), Chief Information Security Officer (CISO), and legal counsel. To simplify decision-making for leadership, use an executive risk scorecard – categorizing risks as green, amber, or red – to present technical audit findings in a way that aligns with business priorities. For high-risk use cases, such as systems for hiring or credit scoring, ensure you conduct mandatory conformity assessments and external audits to uncover potential vulnerabilities.
External penetration testing is another critical step to identify overlooked security gaps. If your AI system processes personal data across borders, confirm that Standard Contractual Clauses (SCCs) or equivalent legal safeguards are in place. Update your privacy policies to clearly disclose AI usage, the types of data being processed, and the logic behind decisions. Treating compliance as a foundational part of your governance structure can help your organization scale with confidence.
Once you have the necessary executive and legal approvals, move to technical validation to confirm that your AI system meets all operational and security requirements before deployment.
Validate Deployment Readiness
Technical readiness involves more than just functional testing. Use cryptography, digital signatures, and checksums to verify the integrity and origin of your AI model weights before production. These weights, which form the core of your system, should be secured in a Hardware Security Module (HSM) or another secure storage environment to prevent theft. Additionally, establish a "golden dataset" to perform final accuracy and bias testing, and implement automated rollback mechanisms to revert to a stable version if performance issues or security breaches occur.
Your system must also meet deadlines for Data Subject Access Requests (DSARs), which vary by region – 21 days in Malaysia, 30 days in Singapore, and 40 days in Hong Kong.
To address potential risks, ensure compliance measures are robust enough to withstand runtime inspections. As Robert X from the AI Competence Framework highlights:
"Compliance that cannot withstand runtime inspection is latent risk".
Regulators are increasingly moving away from static documentation reviews and are now focusing on live monitoring telemetry and decision logs. Conduct pre-enforcement audit drills to ensure your team can provide traceable decision logs during surprise inspections.
Lastly, establish a strong incident response infrastructure. Form a cross-functional response team that includes technical, legal, ethical, and business stakeholders. Define a clear toolkit of actions, such as model rollbacks, traffic rerouting, or activating emergency human oversight. Schedule mandatory quarterly risk assessments for high-risk systems and annual reviews for lower-risk systems to maintain readiness. With these measures in place, you can confidently transition from pilot testing to full production while ensuring operational stability and compliance.
Conclusion
Bringing AI into workforce contingency planning requires a major shift in how businesses approach continuity. Instead of just reacting to disruptions, aligning AI with contingency goals allows companies to build proactive systems that support real-time operations. It also emphasizes creating a governance framework where compliance becomes a strategic advantage.
The numbers speak for themselves: organizations using AI-driven continuity measures have seen a 34% drop in expenses and a 48% boost in team productivity. AI-powered security automation alone has been shown to cut data breach costs by an average of $2.2 million. For example, Walmart’s AI platform has proven effective in quickly detecting incidents and saving costs. This evolution – from reactive crisis management to predictive resilience – separates businesses that merely endure disruptions from those that thrive.
However, the challenges are real. In 2023, 62% of enterprises experienced at least one AI-related outage. This underscores the importance of having infrastructure that can handle real-time data, secure integrations, and automated failovers. Just as critical is preparing teams through regular simulation drills and cross-functional training. As Robert X from the AI Competence Framework puts it:
"AI governance is no longer a policy layer attached to innovation. It is the control architecture that determines how safely and how fast AI can scale inside an organization".
These steps – technical readiness and team preparation – are essential for deploying AI effectively. Additionally, regulations like the EU AI Act, which can impose fines of up to 7% of global turnover, highlight the serious stakes involved. Building operational resilience means treating governance as a central pillar, not just a checklist.
FAQs
What’s the best first AI use case to pilot for contingency planning?
The smartest way to introduce AI into contingency planning is by starting with customer support, particularly in high-demand areas like ticket resolution, documentation, and escalation. Why? These workflows often deal with large volumes, making them perfect for AI to handle efficiently. The result? Fewer backlogs, quicker response times, and happier customers.
To keep things low-risk, begin with a phased rollout targeting just one workflow. This strategy not only limits potential disruptions but also provides a chance to show early returns on investment, all while seamlessly blending AI into your current systems.
How do we know our data and systems are ready for AI during outages?
Creating a disaster recovery plan specifically designed for AI systems is crucial to ensure resilience and continuity. Start by identifying AI-specific risks – for example, issues like model drift, where an AI model’s performance deteriorates over time due to changing data patterns.
Implement robust monitoring systems to track performance and detect anomalies early. At the same time, define clear governance structures and assign specific roles for response and accountability during incidents. Everyone involved should know their responsibilities when things go wrong.
Regularly test and validate your AI infrastructure to ensure it functions as expected under various conditions. Establish clear benchmarks like Recovery Time Objective (RTO) – the maximum downtime acceptable – and Recovery Point Objective (RPO) – the maximum data loss tolerable. These metrics help maintain smooth operations even during disruptions.
Finally, keep incident response checklists handy. These should guide your team in addressing failures systematically, while ensuring critical evidence is preserved for analysis and improvement.
What governance controls are required before deploying AI to production?
Before rolling out AI into production, it’s crucial to have solid governance measures in place to guarantee safety, compliance, and ethical usage. Start by clearly defining the limits of what your AI systems should and shouldn’t do. Assign specific roles for oversight to ensure accountability, and put safeguards in place, such as ongoing performance checks and audit mechanisms.
Create policies to categorize AI systems based on their risk levels and enforce rules to keep them operating within acceptable boundaries. Documentation is key – maintain thorough records to track decisions and changes over time. On the technical side, secure your training environments, protect your model weights from unauthorized access, and keep a close eye on operations to identify and address potential vulnerabilities. These steps are essential for deploying AI responsibly and safely.



